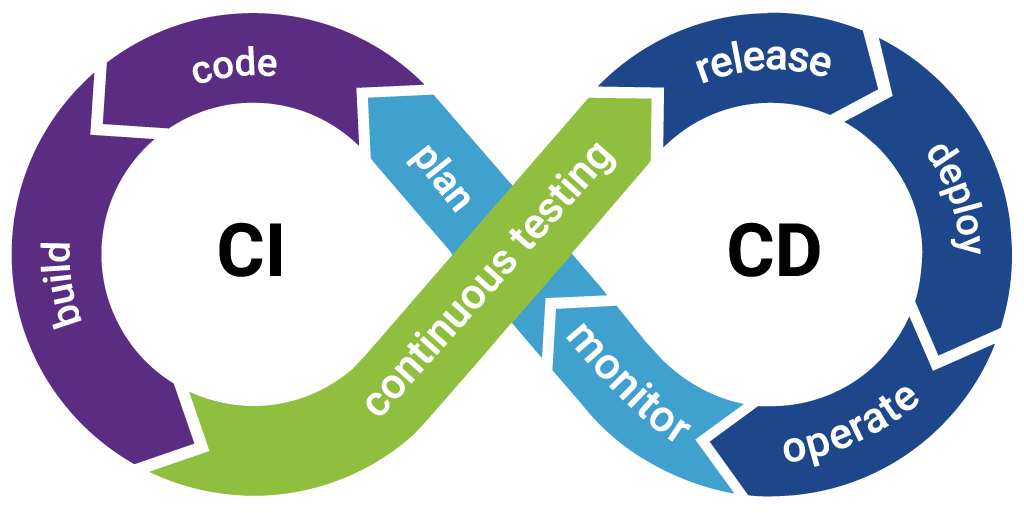
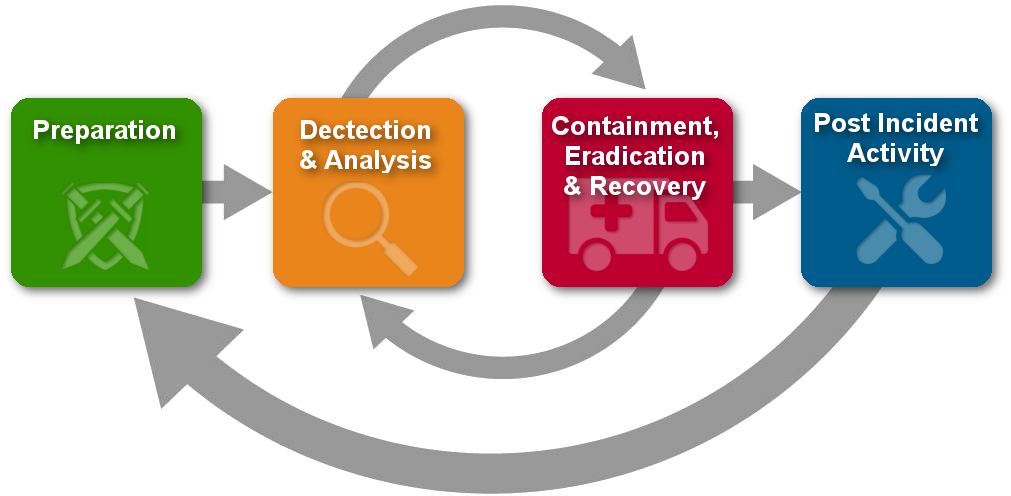
Approach
I tend to use a flexible-inverted-cone approach to any new project.
This serves three (3) purposes:
- It ringfences the project at a high level so that we have a well-defined envelope
- It provides retention and elastic points throughout the discovery and feedback phase
- It enables a focused discussion to occur and drill into the core value the solution will provide
Once we have defined the funnel then we begin to take on the next phase which is the thought-prototyping phase. However, this does not merely consist of wiring-up some code and pushing it to some resources. The prototyping phase consists of several pragmatic steps to evaluate the feasibility of a solution before any code is written or any physical resources allocated. Many of these steps are merely to provoke thought and leverage not only the understanding of the key stakeholders, but also the knowledge of the team and what facilities are currently available and what may become available in the future. Among my favorite methods are:
 Design Thinking
Design Thinking
 Technology Spike Discussion
Technology Spike Discussion
 Stack Discussion
Stack Discussion
 Industry Trends
Industry Trends
 Long-Term Viability
Long-Term Viability
 Paper-Boarding
Paper-Boarding